函数简介(基本原理、信息获取、数据分析、聚合函数�)
数据库科学的一项显著进步,便在于我们不仅仅能够通过数据库软件存储我们的数据,同时我们可以借助由数据库软件提供出来的诸多函数,实现对于数据的分析与精细化管理,乃至于依托这些函数设定数据库本身的行为。
在 PostgreSQL 中,函数便承担着上述的职责,同时联系着关系型数据库自身的特点(PostgreSQL 是一款关系型数据库,因此所有的数据,无论外部输入如何,最终都应当被组织为关系型数据的形式来展开对应的工作),总体呈现出如下的情况(在这里,我按照效用将函数划分为“为数据处理而设计”以及“为某种特定功能而设计”):

同时,如果我们按照实现进行划分,又可以将 PostgreSQL 中的函数,归纳为如下的类别:
- C语言函数
C语言函数可以直接依托 PostgreSQL 内核模块展开工作(PostgreSQL 内核经由纯C语言实现),因此可以对 PostgreSQL 展开最深程度的定制(无论是为 PostgreSQL 引入新的编程语言支持,提供新的索引,新的数据类型,乃至于对于内核的直接修订,C语言函数都可以承担起这些职责来)。
一般而言,我们所接触到的绝大多数的 PostgreSQL 函数,都属于C语言函数,只是对外以 SQL 的形式提供服务。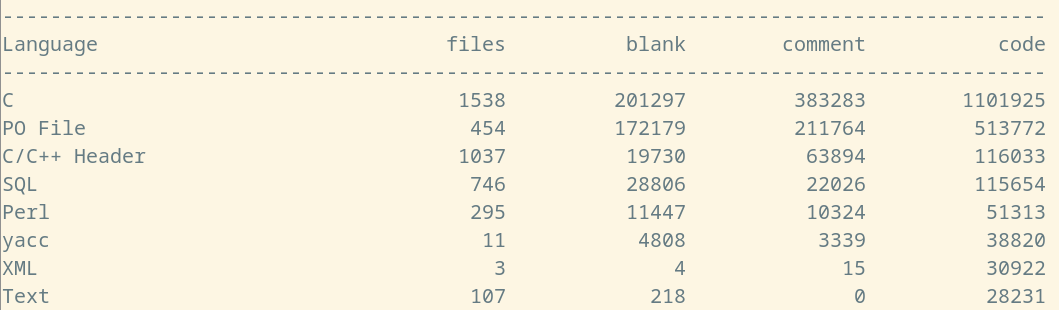 (cloc 程序对 PostgreSQL 17 beta2 版本的源代码统计图表)
(cloc 程序对 PostgreSQL 17 beta2 版本的源代码统计图表) - 过程语言函数
过程语言函数是一些经由其它语言实现,但是经由 SQL 形式面向��用户提供服务的函数,安装过程语言的实质就是向 PostgreSQL 引入一组C语言函数(目的在于使得 PostgreSQL 能够与外部编程语言的解释器展开对接,进而间接支持新的编程语言,如 PL/Python 就提供了对于 Python 语言的支持)。 - SQL 函数
SQL 函数一般而言被用于处理关系型数据,它既不能像C语言函数那样直接依托内部模块展开工作,也无法像过程语言函数那样依托外部库来实现一些复杂的工作,但是对于日常的工作与业务而言(如编写触发器以响应某种情况),SQL 原生编写的函数是一个最佳的选择(在 PostgreSQL 中,我将函数存储过程,用户自定义函数,乃至于聚合函数等都视为函数)。 另外,在 PostgreSQL 中,所有的函数(对用户接口方面),无论是C语言函数还是过程语言函数,最终都要回归到 SQL 函数的形式上面来(我们时刻都要记住 PostgreSQL 是一款关系型数据库,因此一切都要按照关系型数据处理的思路与逻辑而展开)。
在对原理的基本情况,建立了基本的把握之后,现在我们可以使用 PostgreSQL 的函数来展开一定的工作,在实践中建立更为深刻的理解。
使用 PostgreSQL 函数获取一定的数据
为常见的业务场景配备对应的函数是一款数据库由幼稚走向成熟的标志之一,而 PostgreSQL 无疑在这方面有着充�分的积累,让我们参考如下的案例,对此建立一定的了解:
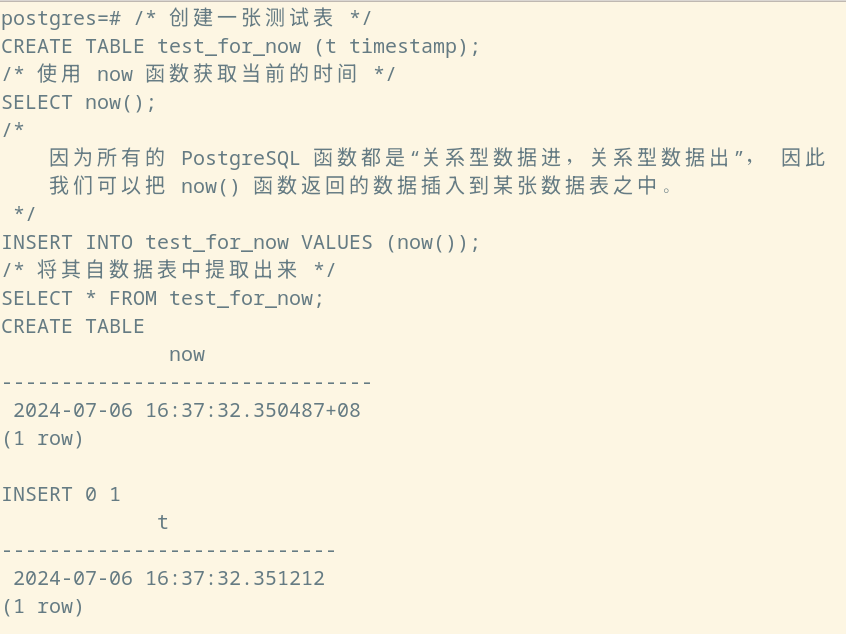
/* 创建一张测试表 */
CREATE TABLE test_for_now (t timestamp);
/* 使用 now 函数获取当前的时间 */
SELECT now();
/*
因为所有的 PostgreSQL 函数都是“关系型数据进,关系型数据出”, 因此
我们可以把 now() 函数返回的数据插入到某张数据表之中。
*/
INSERT INTO test_for_now VALUES (now());
/* 将其自数据表中提取出来 */
SELECT * FROM test_for_now;
更多与时间相关的函数,可以阅读文档《Date/Time Functions and Operators》,在这个基础上,我们可以尝试使用另外一些函数展开数据处理的工作。
使用 PostgreSQL 函数展开简单的数据处理
在文档《String Functions and Operators》中,PostgreSQL 向我们介绍了许多字符串数据处理的函数,现在,让我们选择其中的一些,对 PostgreSQL 应用函数展开数据处理的过程,建立一个基本的理解。
/* 使用 lower 函数转换大写字母为小写 */
SELECT lower('ABCDE');
/* 使用 concat 函数连接字符串 */
SELECT concat('ABC', 'abc');
SELECT CONCAT('ABC', 'abc');
SELECT 'ABC' || 'abc';
PostgreSQL 会自动将函数名转换为小写形式
所以我们使用 concat 与 CONCAT, 甚至是 CoNCat 都可以访问到同一个 concat 函数,这项特性同样也存在于 CREATE TABLE, CREATE SCHEMA 等场景下
PostgreSQL 运算符可以视作为另外一种形式的函数
运算符将参与运算的数据作为参数输入,并提供对应的关系型数据加以返回,因此可以视作为另外一种形式的函数,在实践中,很多对 PostgreSQL 的拓展同样经由提供对特定数据类型的运算符支持入手,进而使得 PostgreSQL 可以适用于更多情况下的场景。
此处的 || 实际起到了和 concat 函数一样的作用,但是因为它没有具体的函数名称(可以理解为有函数之实而无函数之名的匿名函数),所以最终返回时写作了 ?column?,代表数据列名称未知。
聚合函数(Aggregate Functions)
数据的获取与数据的处理都发生于数据列整体被返回之前(我们可以狭义理解为这些都是针对单条的关系型数据的工作),而聚合函数则是一种对于数据整体的统计,它的工作会在数据获取与数据处理完成之后展开,下面我们可以自实践案例中理解窗口函数的作用:
CREATE TABLE series (number INTEGER);
INSERT INTO series SELECT generate_series(1, 10); /* [1, 2, ..., 10] */
SELECT AVG(number) FROM series; /* 调用 avg 函数计算均值 */
SELECT sum(number) FROM series; /* 调用 sum 函数计算和值 */
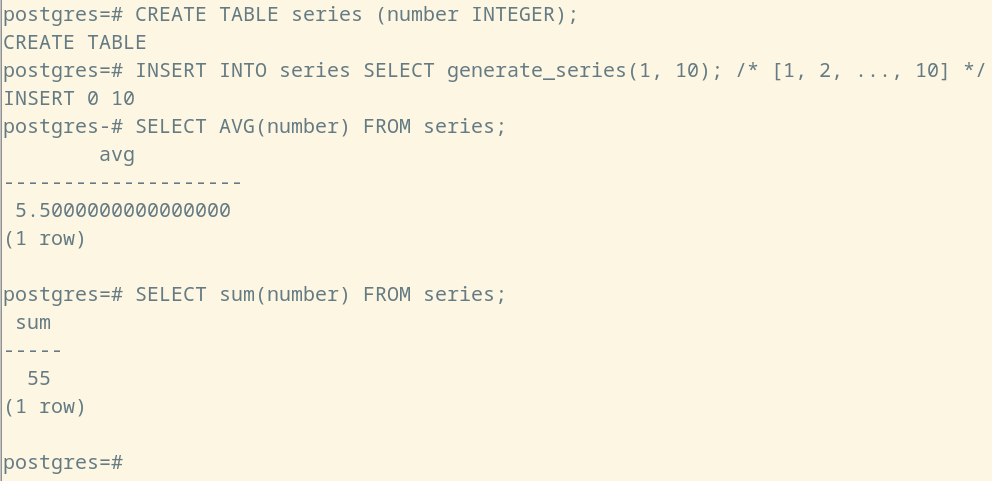
因为是对于整体数据列的统计,因此聚合函数将会在单项数据列全部返回之后再展开对应的工作,由此也就使得我们能够获取到数据列的某项事关整体的特征数据。
窗口函数(Window Function)是一种范围更加细化的聚合函数
相较于对整体数据列的统计,很多时候,我们更加期待能够对更加细化的数据列展开统计的操作,这就像许多人数众多的景区不仅会将自身划分为数个区域用于分散人流,也会将区域内的各处景观分块管理用于应对人潮一样,窗口函数的目标往往会对二次划分以后的数据列展开统计工作(但如果我们二次划分后的数据块依旧是与传递之前的整体数据列完全一样,即实际上没有二次划分的话,那么窗口函数的实际内涵将会同聚合函数保持一致,即都是针对于整体数据列展开某种统计工作)。

有关窗口函数的讨论可以参考文档中《Window Functions》部分(注意即使是同版本 PostgreSQL,也会存在两篇同标题但内容不同的文档,但读者都可以选择阅读,他们从不同的角度与深度讨论了窗口函数),这里因为我们尚未论述分组查询语句,所以不便展开过多讨论。
系统管理函数(System Administration Functions)
前面我们所论述的函数,主�要集中于对于数据的管理与分析上面,而这里我们所论述的函数,则主要围绕 PostgreSQL 本身的行为设置而展开。他们在文档《System Administration Functions》 处有一个集中的讨论,感兴趣的读者可以阅读相关的部分。
在这里,我们向读者介绍 current_setting 函数,它将向我们展现 PostgreSQL 某项运行时参数的设置情况。
/* 尝试让 PostgreSQL 输出当前的客户端名称 */
SELECT current_setting('application_name');
/* 设置客户端名称为 Wen Yi */
SET 'application_name' to 'Wen Yi';
/* 再一次输出 */
SELECT current_setting('application_name');
![current_setting]current_setting.png)
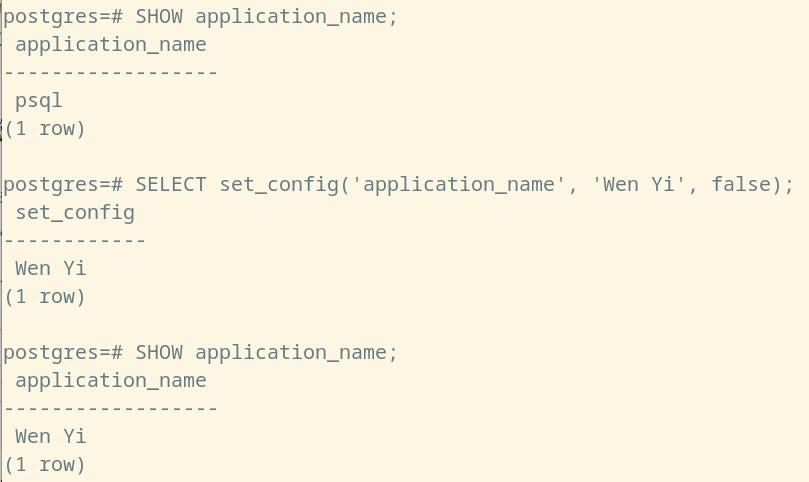
实际上,使用 set_config 函数与 SHOW 指令可以发挥出目前的 'SET' 函数与 'current_setting' 函数一样的作用,我们希望借此能够让读者可以初步对于外部形式与内部实质的关系,有一个基本的了解,参考如下:
SHOW application_name;
SELECT set_config('application_name', 'Wen Yi', false);
SHOW application_name;
总结
经过阅读这篇文档之后,我们也就对于 PostgreSQL 的函数机制有了一个基本的了解与把握了,未来的诸多工作,就是不断积累用例,深化目前我们所拥有的认识与理解,我们非常鼓励读者将自己的想法积淀到我们的社区之中,共建一个相互学习的 PostgreSQL 生态,既是对于自身的促进,也是我们回馈行业的职责。